Chapter 5 Conjugate Families
In the novel Anna Karenina, Tolstoy wrote “Happy families are all alike; every unhappy family is unhappy in its own way.” In this chapter we will learn about conjugate families, which are all alike in the sense that they make the authors very happy. Read on to learn why.
- Practice building Bayesian models. You will build Bayesian models by practicing how to recognize kernels and make use of proportionality.
- Familiarize yourself with conjugacy. You will learn about what makes a prior conjugate and why this is a helpful property. In brief, conjugate priors make it easier to build posterior models. Conjugate priors spark joy!
Getting started
To prepare for this chapter, note that we’ll be using some new Greek letters throughout our analysis: \(\lambda\) = lambda, \(\mu\) = mu or “mew,” \(\sigma\) = sigma, \(\tau\) = tau, and \(\theta\) = theta. Further, load the packages below.
library(bayesrules)
library(tidyverse)
5.1 Revisiting choice of prior
How do we choose a prior? In Chapters 3 and 4 we used the flexibility of the Beta model to reflect our prior understanding of a proportion parameter \(\pi \in [0,1]\). There are other criteria to consider when choosing a prior model:
- Computational ease
Especially if we don’t have access to computing power, it is helpful if the posterior model is easy to build. - Interpretability
We’ve seen that posterior models are a compromise between the data and the prior model. A posterior model is interpretable, and thus more useful, when you can look at its formulation and identify the contribution of the data relative to that of the prior.
The Beta-Binomial has both of these criteria covered. Its calculation is easy. Once we know the Beta(\(\alpha, \beta\)) prior hyperparameters and the observed data \(Y = y\) for the Bin(\(n, \pi\)) model, the Beta(\(\alpha+y, \beta+n-y\)) posterior model follows. This posterior reflects the influence of the data, through the values of \(y\) and \(n\), relative to the prior hyperparameters \(\alpha\) and \(\beta\). If \(\alpha\) and \(\beta\) are large relative to the sample size \(n\), then the posterior will not budge that much from the prior. However, if the sample size \(n\) is large relative to \(\alpha\) and \(\beta\), then the data will take over and be more influential in the posterior model. In fact, the Beta-Binomial belongs to a larger class of prior-data combinations called conjugate families that enjoy both computational ease and interpretable posteriors. Recall a general definition similar to that from Chapter 3.
Conjugate prior
Let the prior model for parameter \(\theta\) have pdf \(f(\theta)\) and the model of data \(Y\) conditioned on \(\theta\) have likelihood function \(L(\theta|y)\). If the resulting posterior model with pdf \(f(\theta|y) \propto f(\theta)L(\theta|y)\) is of the same model family as the prior, then we say this is a conjugate prior.
To emphasize the utility (and fun!) of conjugate priors, it can be helpful to consider a non-conjugate prior. Let parameter \(\pi\) be a proportion between 0 and 1 and suppose we plan to collect data \(Y\) where, conditional on \(\pi\), \(Y|\pi \sim \text{Bin}(n,\pi)\). Instead of our conjugate \(\text{Beta}(\alpha,\beta)\) prior for \(\pi\), let’s try out a non-conjugate prior with pdf \(f(\pi)\), plotted in Figure 5.1:
\[\begin{equation} f(\pi)=e-e^\pi\; \text{ for } \pi \in [0,1]. \tag{5.1} \end{equation}\]
Though not a Beta pdf, \(f(\pi)\) is indeed a valid pdf since \(f(\pi)\) is non-negative on the support of \(\pi\) and the area under the pdf is 1, i.e., \(\int_0^1 f(\pi)=1\).
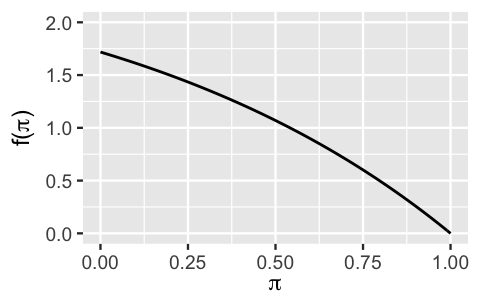
FIGURE 5.1: A non-conjugate prior for \(\pi\).
Next, suppose we observe \(Y = 10\) successes from \(n = 50\) independent trials, all having the same probability of success \(\pi\). The resulting Binomial likelihood function of \(\pi\) is:
\[L(\pi | y=10) = \left(\!\begin{array}{c} 50 \\ 10 \end{array}\!\right) \pi^{10} (1-\pi)^{40} \; \; \text{ for } \pi \in [0,1] .\]
Recall from Chapter 3 that, when we put the prior and the likelihood together, we are already on our path to finding the posterior model with pdf
\[f(\pi | y = 10) \propto f(\pi) L(\pi | y = 10) = (e-e^\pi) \cdot \binom{50}{10} \pi^{10} (1-\pi)^{40}.\]
As we did in Chapter 3, we will drop all constants that do not depend on \(\pi\) since we are only specifying \(f(\pi|y)\) up to a proportionality constant:
\[f(\pi | y ) \propto (e-e^\pi) \pi^{10} (1-\pi)^{40}.\]
Notice here that our non-Beta prior didn’t produce a neat and clean answer for the exact posterior model (fully specified and not up to a proportionality constant). We cannot squeeze this posterior pdf kernel into a Beta box or any other familiar model for that matter. That is, we cannot rewrite \((e-e^\pi) \pi^{10} (1-\pi)^{40}\) so that it shares the same structure as a Beta kernel, \(\pi^{\blacksquare - 1}(1-\pi)^{\blacksquare-1}\). Instead we will need to integrate this kernel in order to complete the normalizing constant, and hence posterior specification:
\[\begin{equation} f(\pi|y=10)= \frac{(e-e^\pi) \pi^{10} (1-\pi)^{40}}{\int_0^1(e-e^\pi) \pi^{10} (1-\pi)^{40}d\pi} \; \; \text{ for } \pi \in [0,1]. \tag{5.2} \end{equation}\]
This is where we really start to feel the pain of not having a conjugate prior! Since this is a particularly unpleasant integral to evaluate, and we’ve been trying to avoid doing any integration altogether, we will leave ourselves with (5.2) as the final posterior. Yikes, what a mess. This is a valid posterior pdf – it’s non-negative and integrates to 1 across \(\pi \in [0,1]\). But it doesn’t have much else going for it. Consider a few characteristics about the posterior model that result from this particular non-conjugate prior (5.1):
- The calculation for this posterior was messy and unpleasant.
- It is difficult to derive any intuition about the balance between the prior information and the data we observed from this posterior model.
- It would be difficult to specify features such as the posterior mean, mode, and standard deviation, a process which would require even more integration.
This leaves us with the question: could we use the conjugate Beta prior and still capture the broader information of the messy non-conjugate prior (5.1)? If so, then we solve the problems of messy calculations and indecipherable posterior models.
Which Beta model would most closely approximate the non-conjugate prior for \(\pi\) (Figure 5.1)?
- Beta(3,1)
- Beta(1,3)
- Beta(2,1)
- Beta(1,2)
The answer to this quiz is d. One way to find the answer is by comparing the non-conjugate prior in Figure 5.1 with plots of the possible Beta prior models. For example, the non-conjugate prior information is pretty well captured by the Beta(1,2) (Figure 5.2):
plot_beta(alpha = 1, beta = 2)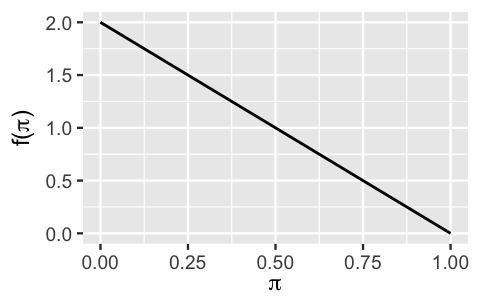
FIGURE 5.2: A conjugate Beta(1,2) prior model for \(\pi\).
5.2 Gamma-Poisson conjugate family
Stop callin’ / Stop callin’ / I don’t wanna think anymore / I got my head and my heart on the dance floor
—Lady Gaga featuring Beyoncé. Lyrics from the song “Telephone.”
Last year, one of this book’s authors got fed up with the number of fraud risk phone calls they were receiving. They set out with a goal of modeling rate \(\lambda\), the typical number of fraud risk calls received per day. Prior to collecting any data, the author’s guess was that this rate was most likely around 5 calls per day, but could also reasonably range between 2 and 7 calls per day. To learn more, they planned to record the number of fraud risk phone calls on each of \(n\) sampled days, \((Y_1,Y_2,\ldots,Y_n)\).
In moving forward with our investigation of \(\lambda\), it’s important to recognize that it will not fit into the familiar Beta-Binomial framework. First, \(\lambda\) is not a proportion limited to be between 0 and 1, but rather a rate parameter that can take on any positive value (e.g., we can’t receive -7 calls per day). Thus, a Beta prior for \(\lambda\) won’t work. Further, each data point \(Y_i\) is a count that can technically take on any non-negative integer in \(\{0,1,2,\ldots\}\), and thus is not limited by some number of trials \(n\) as is true for the Binomial. Not to fret. Our study of \(\lambda\) will introduce us to a new conjugate family, the Gamma-Poisson.
5.2.1 The Poisson data model
The spirit of our analysis starts with a prior understanding of \(\lambda\), the daily rate of fraud risk phone calls. Yet before choosing a prior model structure and tuning this to match our prior understanding, it’s beneficial to identify a model for the dependence of our daily phone call count data \(Y_i\) on the typical daily rate of such calls \(\lambda\). Upon identifying a reasonable data model, we can identify a prior model which can be tuned to match our prior understanding while also mathematically complementing the data model’s corresponding likelihood function. Keeping in mind that each data point \(Y_i\) is a random count that can go from 0 to a really big number, \(Y \in \{0,1,2,\ldots\}\), the Poisson model, described in its general form below, makes a reasonable candidate for modeling this data.
The Poisson model
Let discrete random variable \(Y\) be the number of independent events that occur in a fixed amount of time or space, where \(\lambda > 0\) is the rate at which these events occur. Then the dependence of \(Y\) on parameter \(\lambda\) can be modeled by the Poisson. In mathematical notation:
\[Y | \lambda \sim \text{Pois}(\lambda).\]
Correspondingly, the Poisson model is specified by pmf
\[\begin{equation} f(y|\lambda) = \frac{\lambda^y e^{-\lambda}}{y!}\;\; \text{ for } y \in \{0,1,2,\ldots\} \tag{5.3} \end{equation}\]
where \(f(y|\lambda)\) sums to one across \(y\), \(\sum_{y=0}^\infty f(y|\lambda) = 1\). Further, a Poisson random variable \(Y\) has equal mean and variance,
\[\begin{equation} E(Y|\lambda) = \text{Var}(Y|\lambda) = \lambda . \tag{5.4} \end{equation}\]
Figure 5.3 illustrates the Poisson pmf (5.3) under different rate parameters \(\lambda\). In general, as the rate of events \(\lambda\) increases, the typical number of events increases, the variability increases, and the skew decreases. For example, when events occur at a rate of \(\lambda = 1\), the model is heavily skewed toward observing a small number of events – we’re most likely to observe 0 or 1 events, and rarely more than 3. In contrast, when events occur at a higher rate of \(\lambda = 5\), the model is roughly symmetric and more variable – we’re most likely to observe 4 or 5 events, though have a reasonable chance of observing anywhere between 1 and 10 events.
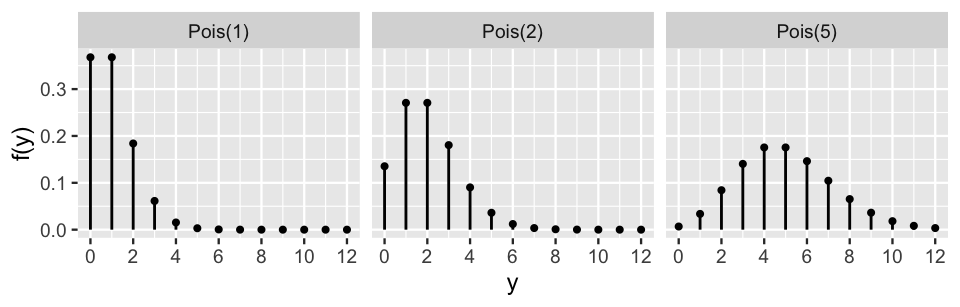
FIGURE 5.3: Poisson pmfs with different rate parameters.
Let \((Y_1, Y_2, \ldots, Y_n)\) denote the number of fraud risk calls we observed on each of the \(n\) days in our data collection period. We assume that the daily number of calls might differ from day to day and can be independently modeled by the Poisson. Thus, on each day \(i\),
\[Y_i | \lambda \stackrel{ind}{\sim} \text{Pois}(\lambda)\]
with unique pmf
\[f(y_i|\lambda) = \frac{\lambda^{y_i}e^{-\lambda}}{y_i!}\;\; \text{ for } y_i \in \{0,1,2,\ldots\} .\]
Yet in weighing the evidence of the phone call data, we won’t want to analyze each individual day. Rather, we’ll need to process the collective or joint information in our \(n\) data points. This information is captured by the joint probability mass function.
Joint probability mass function
Let \((Y_1,Y_2,\ldots,Y_n)\) be an independent sample of random variables and \(\vec{y} = (y_1,y_2,\ldots,y_n)\) be the corresponding vector of observed values. Further, let \(f(y_i | \lambda)\) denote the pmf of an individual observed data point \(Y_i = y_i\). Then by the assumption of independence, the following joint pmf specifies the randomness in and plausibility of the collective sample:
\[\begin{equation} f(\vec{y} | \lambda) = \prod_{i=1}^n f(y_i | \lambda) = f(y_1 | \lambda) \cdot f(y_2 | \lambda) \cdot \cdots \cdot f(y_n | \lambda) . \tag{5.5} \end{equation}\]
Connecting concepts
This product is analogous to the joint probability of independent events being the product of the marginal probabilities, \(P(A \cap B) = P(A)P(B)\).
The joint pmf for our fraud risk call sample follows by applying the general definition (5.5) to our Poisson pmfs. Letting the number of calls on each day \(i\) be \(y_i \in \{0,1,2,\ldots\}\),
\[\begin{equation} f(\vec{y} | \lambda) = \prod_{i=1}^{n}f(y_i | \lambda) = \prod_{i=1}^{n}\frac{\lambda^{y_i}e^{-\lambda}}{y_i!} . \tag{5.6} \end{equation}\]
This looks like a mess, but it can be simplified. In this simplification, it’s important to recognize that we have \(n\) unique data points \(y_i\), not \(n\) copies of the same data point \(y\). Thus, we need to pay careful attention to the \(i\) subscripts. It follows that
\[\begin{split} f(\vec{y} | \lambda) & = \frac{\lambda^{y_1}e^{-\lambda}}{y_1!} \cdot \frac{\lambda^{y_2}e^{-\lambda}}{y_2!} \cdots \frac{\lambda^{y_n}e^{-\lambda}}{y_n!} \\ & = \frac{\left[\lambda^{y_1}\lambda^{y_2} \cdots \lambda^{y_n}\right] \left[e^{-\lambda}e^{-\lambda} \cdots e^{-\lambda}\right]}{y_1! y_2! \cdots y_n!} \\ & =\frac{\lambda^{\sum y_i}e^{-n\lambda}}{\prod_{i=1}^n y_i!} \\ \end{split}\]
where we’ve simplified the products in the final line by appealing to the properties below.
Simplifying products
Let \((x,y,a,b)\) be a set of constants. Then we can utilize the following facts when simplifying products involving exponents:
\[\begin{equation} x^ax^b = x^{a + b} \;\; \text{ and } \;\; x^ay^a = (xy)^a \tag{5.7} \end{equation}\]
Once we observe actual sample data, we can flip this joint pmf on its head to define the likelihood function of \(\lambda\). The Poisson likelihood function is equivalent in formula to the joint pmf \(f(\vec{y}|\lambda)\), yet is a function of \(\lambda\) which helps us assess the compatibility of different possible \(\lambda\) values with our observed collection of sample data \(\vec{y}\):
\[\begin{equation} L(\lambda | \vec{y}) = \frac{\lambda^{\sum y_i}e^{-n\lambda}}{\prod_{i=1}^n y_i!} \propto \lambda^{\sum y_i}e^{-n\lambda} \;\; \text{ for } \lambda > 0. \tag{5.6} \end{equation}\]
It is convenient to represent the likelihood function up to a proportionality constant here, especially since \(\prod y_i!\) will be cumbersome to calculate when \(n\) is large, and what we really care about in the likelihood is \(\lambda\). And when we express the likelihood up to a proportionality constant, note that the sum of the data points (\(\sum y_i\)) and the number of data points (\(n\)) is all the information that is required from the data. We don’t need to know the value of each individual data point \(y_i\). Taking this for a spin with real data points later in our analysis will provide some clarity.
5.2.2 Potential priors
The Poisson data model provides one of two key pieces for our Bayesian analysis of \(\lambda\), the daily rate of fraud risk calls. The other key piece is a prior model for \(\lambda\). Our original guess was that this rate is most likely around 5 calls per day, but could also reasonably range between 2 and 7 calls per day. In order to tune a prior to match these ideas about \(\lambda\), we first have to identify a reasonable probability model structure.
Remember here that \(\lambda\) is a positive and continuous rate, meaning that \(\lambda\) does not have to be a whole number. Accordingly, a reasonable prior probability model will also have continuous and positive support, i.e., be defined on \(\lambda > 0\). There are several named and studied probability models with this property, including the \(F\), Weibull, and Gamma. We don’t dig into all of these in this book. Rather, to make the \(\lambda\) posterior model construction more straightforward and convenient, we’ll focus on identifying a conjugate prior model.
Suppose we have a random sample of Poisson random variables \((Y_1, Y_2, \ldots, Y_n)\) with likelihood function \(L(\lambda | \vec{y})\propto \lambda^{\sum y_i}e^{-n\lambda}\) for \(\lambda > 0\). What do you think would provide a convenient conjugate prior model for \(\lambda\)? Why?
- A “Gamma” model with pdf \(f(\lambda) \propto \lambda^{s - 1} e^{-r \lambda}\)
- A “Weibull” model with pdf \(f(\lambda) \propto \lambda^{s - 1} e^{(-r \lambda)^s}\)
- A special case of the “F” model with pdf \(f(\lambda) \propto \lambda^{\frac{s}{2} - 1}\left( 1 + \lambda\right)^{-s}\)
The answer is a. The Gamma model will provide a conjugate prior for \(\lambda\) when our data has a Poisson model. You might have guessed this from the section title (clever). You might also have guessed this from the shared features of the Poisson likelihood function \(L(\lambda|\vec{y})\) (5.6) and the Gamma pdf \(f(\lambda)\). Both are proportional to
\[\lambda^{\blacksquare}e^{-\blacksquare\lambda}\]
with differing \(\blacksquare\). In fact, we’ll prove that combining the prior and likelihood produces a posterior pdf with this same structure. That is, the posterior will be of the same Gamma model family as the prior. First, let’s learn more about the Gamma model.
5.2.3 Gamma prior
The Gamma & Exponential models
Let \(\lambda\) be a continuous random variable which can take any positive value, i.e., \(\lambda > 0\). Then the variability in \(\lambda\) might be well modeled by a Gamma model with shape hyperparameter \(s > 0\) and rate hyperparameter \(r > 0\):
\[\lambda \sim \text{Gamma}(s, r) .\]
The Gamma model is specified by continuous pdf
\[\begin{equation} f(\lambda) = \frac{r^s}{\Gamma(s)} \lambda^{s-1} e^{-r\lambda} \;\; \text{ for } \lambda > 0. \tag{5.8} \end{equation}\]
Further, the central tendency and variability in \(\lambda\) are measured by:
\[\begin{equation} \begin{split} E(\lambda) & = \frac{s}{r} \\ \text{Mode}(\lambda) & = \frac{s - 1}{r} \;\; \text{ for } s \ge 1 \\ \text{Var}(\lambda) & = \frac{s}{r^2}. \\ \end{split} \tag{5.9} \end{equation}\]
The Exponential model is a special case of the Gamma with shape \(s = 1\), \(\text{Gamma}(1,r)\):
\[\lambda \sim \text{Exp}(r).\]
Notice that the Gamma model depends upon two hyperparameters, \(r\) and \(s\). Assess your understanding of how these hyperparameters impact the Gamma model properties in the following quiz.37
Figure 5.4 illustrates how different shape and rate hyperparameters impact the Gamma pdf (5.8). Based on these plots:
How would you describe the typical behavior of a Gamma(\(s,r\)) variable \(\lambda\) when \(s > r\) (e.g., Gamma(2,1))?
- Right-skewed with a mean greater than 1.
- Right-skewed with a mean less than 1.
- Symmetric with a mean around 1.
Using the same options as above, how would you describe the typical behavior of a Gamma(\(s,r\)) variable \(\lambda\) when \(s < r\) (e.g., Gamma(1,2))?
For which model is there greater variability in the plausible values of \(\lambda\), Gamma(20,20) or Gamma(20,100)?
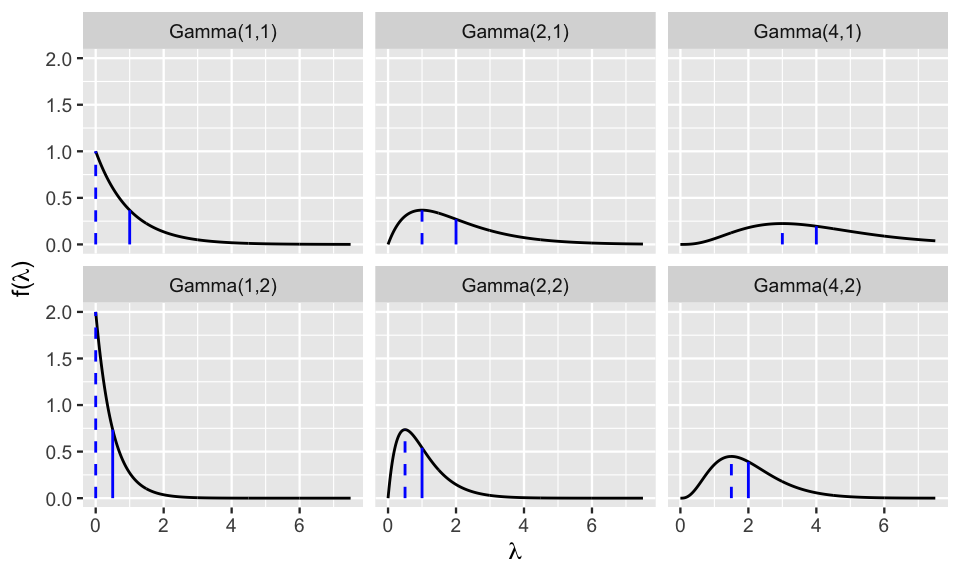
FIGURE 5.4: Gamma models with different hyperparameters. The dashed and solid vertical lines represent the modes and means, respectively.
In general, Figure 5.4 illustrates that \(\lambda \sim \text{Gamma}(s,r)\) variables are positive and right skewed. Further, the general shape and rate of decrease in the skew are controlled by hyperparameters \(s\) and \(r\). The quantitative measures of central tendency and variability in (5.9) provide some insight. For example, notice that the mean of \(\lambda\), \(E(\lambda) = s/r\), is greater than 1 when \(s > r\) and less than 1 when \(s < r\). Further, as \(s\) increases relative to \(r\), the skew in \(\lambda\) decreases and the variability, \(\text{Var}(\lambda) = s / r^2\), increases.
Now that we have some intuition for how the Gamma(\(s,r\)) model works, we can tune it to reflect our prior information about the daily rate of fraud risk phone calls \(\lambda\). Recall our earlier assumption that \(\lambda\) is about 5, and most likely somewhere between 2 and 7. Our Gamma(\(s,r\)) prior should have similar patterns. For example, we want to pick \(s\) and \(r\) for which \(\lambda\) tends to be around 5,
\[E(\lambda) = \frac{s}{r} \approx 5 .\]
This can be achieved by setting \(s\) to be 5 times \(r\), \(s = 5r\).
Next we want to make sure that most values of our Gamma(\(s, r\)) prior are between 2 and 7.
Through some trial and error within these constraints, and plotting various Gamma models using plot_gamma() in the bayesrules package, we find that the Gamma(10,2) features closely match the central tendency and variability in our prior understanding (Figure 5.5).
Thus, a reasonable prior model for the daily rate of fraud risk phone calls is
\[\lambda \sim \text{Gamma}(10,2)\]
with prior pdf \(f(\lambda)\) following from plugging \(s = 10\) and \(r = 2\) into (5.8).
\[f(\lambda) = \frac{2^{10}}{\Gamma(10)} \lambda^{10-1} e^{-2\lambda} \;\; \text{ for } \lambda > 0.\]
# Plot the Gamma(10, 2) prior
plot_gamma(shape = 10, rate = 2)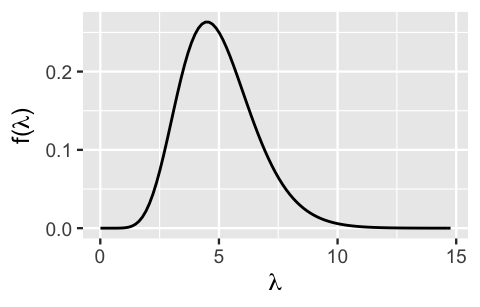
FIGURE 5.5: The pdf of a Gamma(10,2) prior for \(\lambda\), the daily rate of fraud risk calls.
5.2.4 Gamma-Poisson conjugacy
As we discussed at the start of this chapter, conjugate families can come in handy. Fortunately for us, using a Gamma prior for a rate parameter \(\lambda\) and a Poisson model for corresponding count data \(Y\) is another example of a conjugate family. This means that, spoiler, the posterior model for \(\lambda\) will also have a Gamma model with updated parameters. We’ll state and prove this in the general setting before applying the results to our phone call situation.
The Gamma-Poisson Bayesian model
Let \(\lambda > 0\) be an unknown rate parameter and \((Y_1,Y_2,\ldots,Y_n)\) be an independent \(\text{Pois}(\lambda)\) sample. The Gamma-Poisson Bayesian model complements the Poisson structure of data \(Y\) with a Gamma prior on \(\lambda\):
\[\begin{split} Y_i | \lambda & \stackrel{ind}{\sim} \text{Pois}(\lambda) \\ \lambda & \sim \text{Gamma}(s, r) .\\ \end{split}\]
Upon observing data \(\vec{y} = (y_1,y_2,\ldots,y_n)\), the posterior model of \(\lambda\) is also a Gamma with updated parameters:
\[\begin{equation} \lambda|\vec{y} \; \sim \; \text{Gamma}\left(s + \sum y_i, \; r + n\right) . \tag{5.10} \end{equation}\]
Let’s prove this result. In general, recall that the posterior pdf of \(\lambda\) is proportional to the product of the prior pdf and likelihood function defined by (5.8) and (5.6), respectively:
\[f(\lambda|\vec{y}) \propto f(\lambda)L(\lambda|\vec{y}) = \frac{r^s}{\Gamma(s)} \lambda^{s-1} e^{-r\lambda} \cdot \frac{\lambda^{\sum y_i}e^{-n\lambda}}{\prod y_i!} \;\;\; \text{ for } \lambda > 0.\]
Next, remember that any non-\(\lambda\) multiplicative constant in the above equation can be “proportional-ed” out. Thus, boiling the prior pdf and likelihood function down to their kernels, we get
\[\begin{split} f(\lambda|\vec{y}) & \propto \lambda^{s-1} e^{-r\lambda} \cdot \lambda^{\sum y_i}e^{-n\lambda} \\ & = \lambda^{s + \sum y_i - 1} e^{-(r+n)\lambda} \\ \end{split}\]
where the final line follows by combining like terms. What we’re left with here is the kernel of the posterior pdf. This particular kernel corresponds to the pdf of a Gamma model (5.8), with shape parameter \(s + \sum y_i\) and rate parameter \(r + n\). Thus, we’ve proven that
\[ \lambda|\vec{y} \; \sim \; \text{Gamma}\bigg(s + \sum y_i, r + n \bigg) .\]
Let’s apply this result to our fraud risk calls. There we have a Gamma(10,2) prior for \(\lambda\), the daily rate of calls. Further, on four separate days in the second week of August, we received \(\vec{y} = (y_1,y_2,y_3,y_4) = (6,2,2,1)\) such calls. Thus, we have a sample of \(n = 4\) data points with a total of 11 fraud risk calls and an average of 2.75 phone calls per day:
\[\sum_{i=1}^4y_i = 6 + 2 + 2 + 1 = 11 \;\;\;\; \text{ and } \;\;\;\; \overline{y} = \frac{\sum_{i=1}^4y_i}{4} = 2.75 .\]
Plugging this data into (5.6), the resulting Poisson likelihood function of \(\lambda\) is
\[L(\lambda | \vec{y}) = \frac{\lambda^{11}e^{-4\lambda}}{6!\times2!\times2!\times1!} \propto \lambda^{11}e^{-4\lambda} \;\;\;\; \text{ for } \lambda > 0 .\]
We visualize a portion of \(L(\lambda | \vec{y})\) for \(\lambda\) between 0 and 10 using the plot_poisson_likelihood() function in the bayesrules package.
Here, y is the vector of data values and lambda_upper_bound is the maximum value of \(\lambda\) to view on the x-axis.
(Why can’t we visualize the whole likelihood?
Because \(\lambda \in (0, \infty)\) and this book would be pretty expensive if we had infinite pages.)
plot_poisson_likelihood(y = c(6, 2, 2, 1), lambda_upper_bound = 10)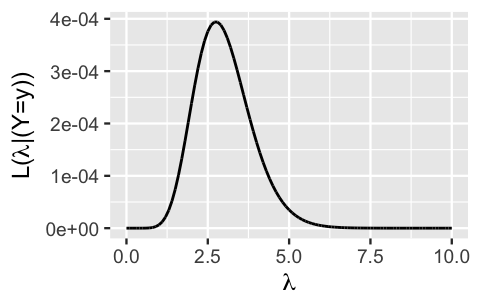
FIGURE 5.6: The likelihood function of \(\lambda\), the daily rate of fraud risk calls, given a four-day sample of phone call data.
The punchline is this. Underlying rates \(\lambda\) of between one to five fraud risk calls per day are consistent with our phone call data. And across this spectrum, rates near 2.75 are the most compatible with this data. This makes sense. The Poisson data model assumes that \(\lambda\) is the underlying average daily phone call count, \(E(Y_i | \lambda) = \lambda\). As such, we’re most likely to observe a sample with an average daily phone call rate of \(\overline{y} = 2.75\) when the underlying rate \(\lambda\) is also 2.75.
Combining these observations with our Gamma(10,2) prior model of \(\lambda\), it follows from (5.10) that the posterior model of \(\lambda\) is a Gamma with an updated shape parameter of 21 (\(s + \sum y_i = 10 + 11\)) and rate parameter of 6 (\(r + n = 2 + 4\)):
\[\lambda|\vec{y} \; \sim \; \text{Gamma}(21, 6) .\]
We can visualize the prior pdf, scaled likelihood function, and posterior pdf for \(\lambda\) all in a single plot with the plot_gamma_poisson() function in the bayesrules package.
How magical.
For this function to work, we must specify a few things: the prior shape and rate hyperparameters as well as the information from our data, the observed total number of phone calls sum_y \((\sum y_i)\) and the sample size n:
plot_gamma_poisson(shape = 10, rate = 2, sum_y = 11, n = 4)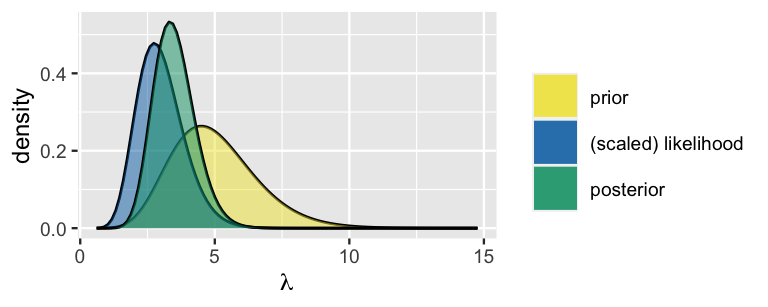
FIGURE 5.7: The Gamma-Poisson model of \(\lambda\), the daily rate of fraud risk calls.
Our posterior notion about the daily rate of fraud calls is, of course, a compromise between our vague prior and the observed phone call data. Since our prior notion was quite variable in comparison to the strength in our sample data, the posterior model of \(\lambda\) is more in sync with the data. Specifically, utilizing the properties of the Gamma(10,2) prior and Gamma(21,6) posterior as defined by (5.9), notice that our posterior understanding of the typical daily rate of phone calls dropped from 5 to 3.5 per day:
\[E(\lambda) = \frac{10}{2} = 5 \;\; \text{ and } \;\; E(\lambda | \vec{y}) = \frac{21}{6} = 3.5 .\]
Though a compromise between the prior mean and data mean, this posterior mean is closer to the data mean of \(\overline{y} = 2.75\) calls per day.
Hot tip
The posterior mean will always be between the prior mean and the data mean. If your posterior mean falls outside that range, it indicates that you made an error and should retrace some steps.
Further, with the additional information about \(\lambda\) from the data, the variability in our understanding of \(\lambda\) drops by more than half, from a standard deviation of 1.581 to 0.764 calls per day:
\[\text{SD}(\lambda) = \sqrt{\frac{10}{2^2}} = 1.581 \;\; \text{ and } \;\; \text{SD}(\lambda | \vec{y}) = \sqrt{\frac{21}{6^2}} = 0.764 .\]
The convenient summarize_gamma_poisson() function in the bayesrules package, which uses the same arguments as plot_gamma_poisson(), helps us contrast the prior and posterior models and confirms the results above:
summarize_gamma_poisson(shape = 10, rate = 2, sum_y = 11, n = 4)
model shape rate mean mode var sd
1 prior 10 2 5.0 4.500 2.5000 1.5811
2 posterior 21 6 3.5 3.333 0.5833 0.76385.3 Normal-Normal conjugate family
We now have two conjugate families in our toolkit: the Beta-Binomial and the Gamma-Poisson. But many more conjugate families exist! It’s impossible to cover them all, but there is a third conjugate family that’s especially helpful to know: the Normal-Normal. Consider a data story. As scientists learn more about brain health, the dangers of concussions (hence of activities in which participants sustain repeated concussions) are gaining greater attention (Bachynski 2019). Among all people who have a history of concussions, we are interested in \(\mu\), the average volume (in cubic centimeters) of a specific part of the brain: the hippocampus. Though we don’t have prior information about this group in particular, Wikipedia tells us that among the general population of human adults, both halves of the hippocampus have a volume between 3.0 and 3.5 cubic centimeters.38 Thus, the total hippocampal volume of both sides of the brain is between 6 and 7 \(\text{cm}^3\). Using this as a starting point, we’ll assume that the mean hippocampal volume among people with a history of concussions, \(\mu\), is also somewhere between 6 and 7 \(\text{cm}^3\), with an average of 6.5. We’ll balance this prior understanding with data on the hippocampal volumes of \(n = 25\) subjects, \((Y_1,Y_2,\ldots,Y_n)\), using the Normal-Normal Bayesian model.
5.3.1 The Normal data model
Again, the spirit of our Bayesian analysis starts with our prior understanding of \(\mu\). Yet the specification of an appropriate prior model structure for \(\mu\) (which we can then tune) can be guided by first identifying a model for the dependence of our data \(Y_i\) upon \(\mu\). Since hippocampal volumes \(Y_i\) are measured on a continuous scale, there are many possible common models of the variability in \(Y_i\) from person to person: Beta, Exponential, Gamma, Normal, F, etc. From this list, we can immediately eliminate the Beta model – it assumes that \(Y_i \in [0,1]\), whereas hippocampal volumes tend to be around 6.5 \(\text{cm}^3\). Among the remaining options, the Normal model is quite reasonable – biological measurements like hippocampal volume are often symmetrically or Normally distributed around some global average, here \(\mu\).
The Normal model
Let \(Y\) be a continuous random variable which can take any value between \(-\infty\) and \(\infty\), i.e., \(Y \in (-\infty,\infty)\). Then the variability in \(Y\) might be well represented by a Normal model with mean parameter \(\mu \in (-\infty, \infty)\) and standard deviation parameter \(\sigma > 0\):
\[Y \sim N(\mu, \sigma^2).\]
The Normal model is specified by continuous pdf
\[\begin{equation} f(y) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\bigg[{-\frac{(y-\mu)^2}{2\sigma^2}}\bigg] \;\; \text{ for } y \in (-\infty,\infty) \tag{5.11} \end{equation}\]
and has the following features:
\[\begin{split} E(Y) & = \text{ Mode}(Y) = \mu \\ \text{Var}(Y) & = \sigma^2 \\ \text{SD}(Y) & = \sigma. \\ \end{split}\]
Further, \(\sigma\) provides a sense of scale for \(Y\). Roughly 95% of \(Y\) values will be within 2 standard deviations of \(\mu\):
\[\begin{equation} \mu \pm 2\sigma . \tag{5.12} \end{equation}\]
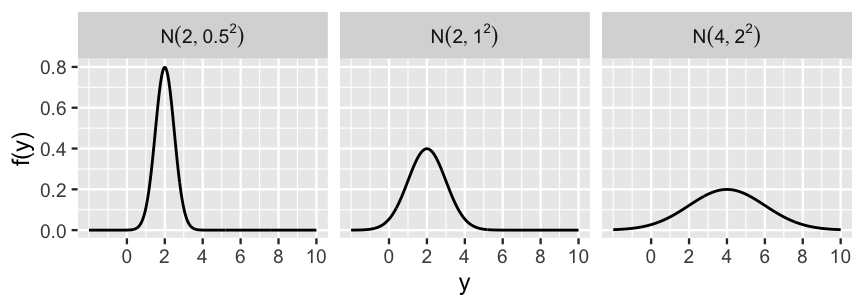
FIGURE 5.8: Normal pdfs with varying mean and standard deviation parameters.
Figure 5.8 illustrates the Normal model under a variety of mean and standard deviation parameter values, \(\mu\) and \(\sigma\).
No matter the parameters, the Normal model is bell-shaped and symmetric around \(\mu\) – thus as \(\mu\) gets larger, the model shifts to the right along with it.
Further, \(\sigma\) controls the variability of the Normal model – as \(\sigma\) gets larger, the model becomes more spread out.
Finally, though a Normal variable \(Y\) can technically range from \(-\infty\) to \(\infty\), the Normal model assigns negligible plausibility to \(Y\) values that are more than 3 standard deviations \(\sigma\) from the mean \(\mu\).
To play around some more, you can plot Normal models using the plot_normal() function from the bayesrules package.
Returning to our brain analysis, we can reasonably assume that the hippocampal volumes of our \(n = 25\) subjects, \((Y_1,Y_2,\ldots,Y_{n})\), are independent and Normally distributed around a mean volume \(\mu\) with standard deviation \(\sigma\). Further, to keep our focus on \(\mu\), we’ll assume throughout our analysis that the standard deviation is known to be \(\sigma = 0.5\) \(\text{cm}^3\).39 This choice of \(\sigma\) suggests that most people have hippocampal volumes within \(2\sigma = 1\) \(\text{cm}^3\) of the average. Thus, the dependence of \(Y_i\) on the unknown mean \(\mu\) is:
\[Y_i | \mu \; \sim \; N(\mu, \sigma^2) .\]
Reasonable doesn’t mean perfect. Though we’ll later see that our hippocampal volume data does exhibit Normal behavior, the Normal model technically assumes that each subject’s hippocampal volume can range from \(-\infty\) to \(\infty\). However, we’re not too worried about this incorrect assumption here. Per our earlier discussion of Figure 5.8, the Normal model will put negligible weight on unreasonable values of hippocampal volume. In general, not letting perfect be the enemy of good will be a theme throughout this book (mainly because there is no perfect).
Accordingly, the joint pdf which describes the collective randomness in our \(n = 25\) subjects’ hippocampal volumes, \((Y_1, Y_2, \ldots, Y_n)\), is the product of the unique Normal pdfs \(f(y_i | \mu)\) defined by (5.11),
\[f(\vec{y} | \mu) = \prod_{i=1}^{n}f(y_i|\mu) = \prod_{i=1}^{n}\frac{1}{\sqrt{2\pi\sigma^2}} \exp\bigg[{-\frac{(y_i-\mu)^2}{2\sigma^2}}\bigg] .\]
Once we observe our sample data \(\vec{y}\), we can flip the joint pdf on its head to obtain the Normal likelihood function of \(\mu\), \(L(\mu|\vec{y}) = f(\vec{y}|\mu)\). Remembering that we’re assuming \(\sigma\) is a known constant, we can simplify the likelihood up to a proportionality constant by dropping the terms that don’t depend upon \(\mu\). Then for \(\mu \in (-\infty, \infty)\),
\[L(\mu |\vec{y}) \propto \prod_{i=1}^{n} \exp\bigg[{-\frac{(y_i-\mu)^2}{2\sigma^2}}\bigg] = \exp\bigg[{-\frac{\sum_{i=1}^n(y_i-\mu)^2}{2\sigma^2}}\bigg] .\] Through a bit more rearranging (which we encourage you to verify if, like us, you enjoy algebra), we can make this even easier to digest by using the sample mean \(\bar{y}\) and sample size \(n\) to summarize our data values:
\[\begin{equation} L(\mu | \vec{y}) \propto \exp\bigg[{-\frac{(\bar{y}-\mu)^2}{2\sigma^2/n}}\bigg] \;\;\;\; \text{ for } \; \mu \in (-\infty, \infty). \tag{5.13} \end{equation}\]
Don’t forget the whole point of this exercise! Specifying a model for the data along with its corresponding likelihood function provides the tools we’ll need to assess the compatibility of our data \(\vec{y}\) with different values of \(\mu\) (once we actually collect that data).
5.3.2 Normal prior
With the likelihood in place, let’s formalize a prior model for \(\mu\), the mean hippocampal volume among people that have a history of concussions. By the properties of the \(Y_i|\mu \sim N(\mu, \sigma^2)\) data model, the Normal mean parameter \(\mu\) can technically take any value between \(-\infty\) and \(\infty\). Thus, a Normal prior for \(\mu\), which is also defined for \(\mu \in (-\infty, \infty)\), makes a reasonable choice. Specifically, we’ll assume that \(\mu\) itself is Normally distributed around some mean \(\theta\) with standard deviation \(\tau\):
\[\mu \sim N(\theta, \tau^2) , \]
where \(\mu\) has prior pdf
\[\begin{equation} f(\mu) = \frac{1}{\sqrt{2\pi\tau^2}} \exp\bigg[{-\frac{(\mu - \theta)^2}{2\tau^2}}\bigg] \;\; \text{ for } \mu \in (-\infty,\infty) . \tag{5.14} \end{equation}\]
Not only does the Normal prior assumption that \(\mu \in (-\infty,\infty)\) match the same assumption of the Normal data model, we’ll prove below that this is a conjugate prior. You might anticipate this result from the fact that the likelihood function \(L(\mu | \vec{y})\) (5.13) and prior pdf \(f(\mu)\) (5.14) are both proportional to
\[\exp\bigg[{-\frac{(\mu - \blacksquare)^2}{2\blacksquare^2}}\bigg]\]
with different \(\blacksquare\).
Using our understanding of a Normal model, we can now tune the prior hyperparameters \(\theta\) and \(\tau\) to reflect our prior understanding and uncertainty about the average hippocampal volume among people that have a history of concussions, \(\mu\). Based on our rigorous Wikipedia research that hippocampal volumes tend to be between 6 and 7 \(\text{cm}^3\), we’ll set the Normal prior mean \(\theta\) to the midpoint, 6.5. Further, we’ll set the Normal prior standard deviation to \(\tau = 0.4\). In other words, by (5.12), we think there’s a 95% chance that \(\mu\) is somewhere between 5.7 and 7.3 \(\text{cm}^3\) (\(6.5 \pm 2*0.4\)). This range is wider, and hence more conservative, than what Wikipedia indicated. Our uncertainty here reflects the fact that we didn’t vet the Wikipedia sources, we aren’t confident that the features for the typical adult translates to people with a history of concussions, and we generally aren’t sure what’s going on here (i.e., we’re not brain experts). Putting this together, our tuned prior model for \(\mu\) is:
\[\mu \sim N(6.5, 0.4^2) .\]
plot_normal(mean = 6.5, sd = 0.4)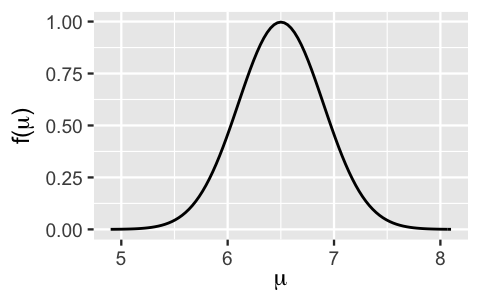
FIGURE 5.9: A Normal prior model for \(\mu\), with mean 6.5 and standard deviation 0.4.
5.3.3 Normal-Normal conjugacy
To obtain our posterior model of \(\mu\) we must combine the information from our prior and our data. Again, we were clever to pick a Normal prior model – the Normal-Normal is another convenient conjugate family! Thus, the posterior model for \(\mu\) will also be Normal with updated parameters that are informed by the prior and observed data.
The Normal-Normal Bayesian model
Let \(\mu \in (-\infty,\infty)\) be an unknown mean parameter and \((Y_1,Y_2,\ldots,Y_n)\) be an independent \(N(\mu,\sigma^2)\) sample where \(\sigma\) is assumed to be known. The Normal-Normal Bayesian model complements the Normal data structure with a Normal prior on \(\mu\):
\[\begin{split} Y_i | \mu & \stackrel{ind}{\sim} N(\mu, \sigma^2) \\ \mu & \sim N(\theta, \tau^2) \\ \end{split}\]
Upon observing data \(\vec{y} = (y_1,y_2,\ldots,y_n)\) with mean \(\overline{y}\), the posterior model of \(\mu\) is also Normal with updated parameters:
\[\begin{equation} \mu|\vec{y} \; \sim \; N\bigg(\theta\frac{\sigma^2}{n\tau^2+\sigma^2} + \bar{y}\frac{n\tau^2}{n\tau^2+\sigma^2}, \; \frac{\tau^2\sigma^2}{n\tau^2+\sigma^2}\bigg) . \tag{5.15} \end{equation}\]
Whooo, that is a mouthful! We provide an optional proof of this result in Section 5.3.4. Even without that proof, we can observe the balance that the Normal posterior (5.15) strikes between the prior and the data. First, the posterior mean is a weighted average of the prior mean \(E(\mu) = \theta\) and the sample mean \(\overline{y}\). Second, the posterior variance is informed by the prior variability \(\tau\) and variability in the data \(\sigma\). Both are impacted by sample size \(n\). First, as \(n\) increases, the posterior mean places less weight on the prior mean and more weight on sample mean \(\overline{y}\):
\[\frac{\sigma^2}{n\tau^2+\sigma^2} \to 0 \;\; \text{ and } \;\; \frac{n\tau^2}{n\tau^2+\sigma^2} \to 1 .\]
Further, as \(n\) increases, the posterior variance decreases:
\[\frac{\tau^2\sigma^2}{n\tau^2+\sigma^2} \to 0 .\]
That is, the more and more data we have, our posterior certainty about \(\mu\) increases and becomes more in sync with the data.
Let’s apply and examine this result in our analysis of \(\mu\), the average hippocampal volume among people that have a history of concussions.
We’ve already built our prior model of \(\mu\), \(\mu \sim N(6.5, 0.4^2)\).
Next, consider some data.
The football data in bayesrules, a subset of the FootballBrain data in the Lock5Data package (Lock et al. 2016), includes results for a cross-sectional study of hippocampal volumes among 75 subjects (Singh et al. 2014): 25 collegiate football players with a history of concussions (fb_concuss), 25 collegiate football players that do not have a history of concussions (fb_no_concuss), and 25 control subjects.
For our analysis, we’ll focus on the \(n = 25\) subjects with a history of concussions (fb_concuss):
# Load the data
data(football)
concussion_subjects <- football %>%
filter(group == "fb_concuss")These subjects have an average hippocampal volume of \(\overline{y}\) = 5.735 \(\text{cm}^3\):
concussion_subjects %>%
summarize(mean(volume))
mean(volume)
1 5.735Further, the hippocampal volumes appear to vary normally from subject to subject, ranging from roughly 4.5 to 7 \(\text{cm}^3\). That is, our assumed Normal data model about individual hippocampal volumes, \(Y_i |\mu \sim N(\mu, \sigma^2)\) with an assumed standard deviation of \(\sigma = 0.5\), seems reasonable:
ggplot(concussion_subjects, aes(x = volume)) +
geom_density()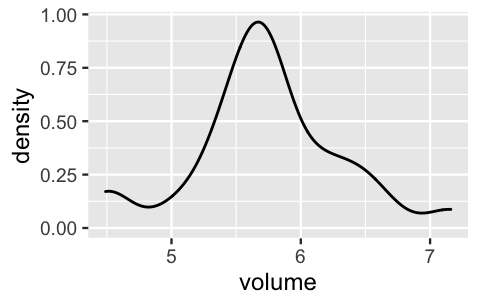
FIGURE 5.10: A density plot of the hippocampal volumes (in cubic centimeters) among 25 subjects that have experienced concussions.
Plugging this information from the data (\(n = 25\), \(\overline{y}\) = 5.735, and \(\sigma = 0.5\)) into (5.13) defines the Normal likelihood function of \(\mu\):
\[L(\mu | \vec{y}) \propto \exp\bigg[{-\frac{(5.735-\mu)^2}{2(0.5^2/25)}}\bigg] \;\;\;\; \text{ for } \; \mu \in (-\infty, \infty).\]
We plot this likelihood function using plot_normal_likelihood(), providing our observed volume data and data standard deviation \(\sigma = 0.5\) (Figure 5.11).
This likelihood illustrates the compatibility of our observed hippocampal data with different \(\mu\) values.
To this end, the hippocampal patterns observed in our data would most likely have arisen if the mean hippocampal volume across all people with a history of concussions, \(\mu\), were between 5.3 and 6.1 \(\text{cm}^3\).
Further, we’re most likely to have observed a mean volume of \(\overline{y} =\) 5.735 among our 25 sample subjects if the underlying population mean \(\mu\) were also 5.735.
plot_normal_likelihood(y = concussion_subjects$volume, sigma = 0.5)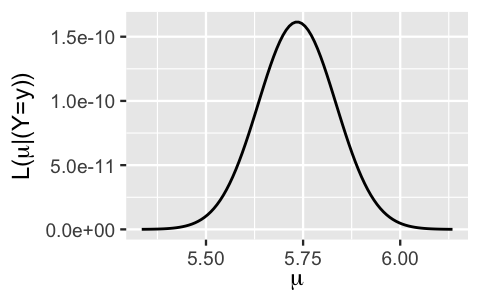
FIGURE 5.11: The Normal likelihood function for mean hippocampal volume \(\mu\).
We now have all necessary pieces to plug into (5.15), and hence to specify the posterior model of \(\mu\):
- our Normal prior model of \(\mu\) had mean \(\theta = 6.5\) and standard deviation \(\tau = 0.4\);
- our \(n = 25\) sample subjects had a sample mean volume \(\bar{y}=5.735\);
- we assumed a known standard deviation among individual hippocampal volumes of \(\sigma = 0.5\).
It follows that the posterior model of \(\mu\) is:
\[\mu | \vec{y} \; \sim \; N\bigg(6.5\cdot\frac{0.5^2}{25\cdot0.4^2+0.5^2} + 5.735\cdot\frac{25\cdot 0.4^2}{25 \cdot 0.4^2+0.5^2}, \; \frac{0.4^2\cdot0.5^2}{25\cdot0.4^2+0.5^2}\bigg).\]
Further simplified,
\[\mu | \vec{y} \; \sim \; N\bigg(5.78, 0.009^2 \bigg)\]
where the posterior mean places roughly 94% of its weight on the data mean (\(\overline{y} = 5.375\)) and only 6% of its weight on the prior mean (\(E(\mu) = 6.5\)):
\[E(\mu|\vec{y}) = 6.5 \cdot 0.0588 + 5.735\cdot 0.9412 = 5.78 .\]
Bringing all of these pieces together, we plot and summarize our Normal-Normal analysis of \(\mu\) using plot_normal_normal() and summarize_normal_normal() in the bayesrules package.
Though a compromise between the prior and data, our posterior understanding of \(\mu\) is more heavily influenced by the latter.
In light of our data, we are much more certain about the mean hippocampal volume among people with a history of concussions, and believe that this figure is somewhere in the range from 5.586 to 5.974 \(\text{cm}^3\) (\(5.78 \pm 2*0.097\)).
plot_normal_normal(mean = 6.5, sd = 0.4, sigma = 0.5,
y_bar = 5.735, n = 25)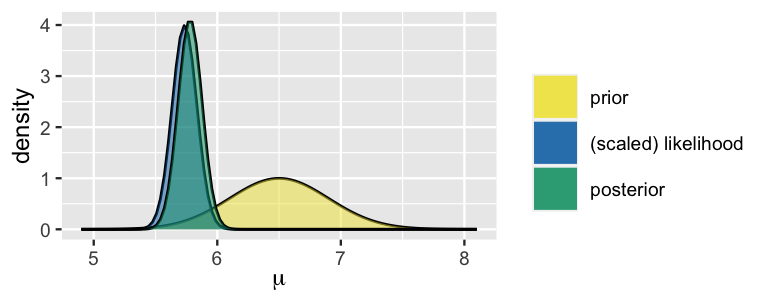
FIGURE 5.12: The Normal-Normal model of \(\mu\), average hippocampal volume.
summarize_normal_normal(mean = 6.5, sd = 0.4, sigma = 0.5,
y_bar = 5.735, n = 25)
model mean mode var sd
1 prior 6.50 6.50 0.160000 0.40000
2 posterior 5.78 5.78 0.009412 0.097015.3.4 Optional: Proving Normal-Normal conjugacy
For completeness sake, we prove here that the Normal-Normal model produces posterior model (5.15). If derivations are not your thing, that’s totally fine. Feel free to skip ahead to the next section and know that you can use this Normal-Normal model with a light heart. Let’s get right into it. The posterior pdf of \(\mu\) is proportional to the product of the Normal prior pdf (5.14) and the likelihood function (5.13). For \(\mu \in (-\infty, \infty)\):
\[f(\mu|\vec{y}) \propto f(\mu)L(\mu|\vec{y}) \propto \exp\bigg[{\frac{-(\mu - \theta)^2}{2\tau^2}}\bigg] \cdot \exp\bigg[{-\frac{(\bar{y}-\mu)^2}{2\sigma^2/n}}\bigg] .\]
Next, we can expand the squares in the exponents and sweep under the rug of proportionality both the \(\theta^2\) in the numerator of the first exponent and the \(\bar{y}^2\) in the numerator of the second exponent:
\[\begin{split} f(\mu|\vec{y}) & \propto \exp\Bigg[{\frac{-\mu^2+2\mu\theta-\theta^2}{2\tau^2}}\Bigg]\exp\Bigg[{\frac{-\mu^2+2\mu\bar{y}-\bar{y}^2}{2\sigma^2/n}}\Bigg] \\ & \propto \exp\Bigg[{\frac{-\mu^2+2\mu\theta}{2\tau^2}}\Bigg]\exp\Bigg[{\frac{-\mu^2+2\mu\bar{y}}{2\sigma^2/n}}\Bigg]. \\ \end{split}\]
Next, we give the exponents common denominators and combine them into a single exponent:
\[\begin{split} f(\mu|\vec{y}) & \propto \exp\Bigg[{\frac{(-\mu^2+2\mu\theta)\sigma^2/n}{2\tau^2\sigma^2/n}}\Bigg]\exp\Bigg[{\frac{(-\mu^2+2\mu\bar{y})\tau^2}{2\tau^2\sigma^2/n}}\Bigg] \\ & \propto \exp\Bigg[{\frac{(-\mu^2+2\mu\theta)\sigma^2 +(-\mu^2+2\mu\bar{y})n\tau^2}{2\tau^2\sigma^2}}\Bigg]. \\ \end{split}\]
Now let’s combine \(\mu\) terms and rearrange so that \(\mu^2\) is by itself:
\[\begin{split} f(\mu|\vec{y}) & \propto \exp\Bigg[{\frac{-\mu^2(n\tau^2+\sigma^2)+2\mu(\theta\sigma^2+ \bar{y}n\tau^2) }{2\tau^2\sigma^2}}\Bigg] \\ & \propto \exp\Bigg[{\frac{-\mu^2+2\mu\left(\frac{\theta\sigma^2 + \bar{y}n\tau^2}{n\tau^2+\sigma^2}\right) }{2(\tau^2\sigma^2) /(n\tau^2+\sigma^2)}}\Bigg]. \\ \end{split}\]
This may seem like too much to deal with, but if you look closely, you can see that we can bring back some constants which do not depend upon \(\mu\) to complete the square in the numerator:
\[\begin{split} f(\mu|\vec{y}) & \propto \exp\Bigg[{\frac{-\bigg(\mu - \frac{\theta\sigma^2 + \bar{y}n\tau^2}{n\tau^2+\sigma^2}\bigg)^2 }{2(\tau^2\sigma^2) /(n\tau^2+\sigma^2)}}\Bigg]. \\ \end{split}\]
This may still seem messy, but once we complete the square, we actually have the kernel of a Normal pdf for \(\mu\), \(\exp\bigg[{-\frac{(\mu - \blacksquare)^2}{2\blacksquare^2}}\bigg]\). By identifying the missing pieces \(\blacksquare\), we can thus conclude that
\[ \mu|\vec{y} \; \sim \; N\left(\frac{\theta\sigma^2+ \bar{y}n\tau^2}{n\tau^2+\sigma^2}, \;{\frac{\tau^2\sigma^2}{n\tau^2+\sigma^2}} \right)\]
where we can reorganize the posterior mean as a weighted average of the prior mean \(\mu\) and data mean \(\overline{y}\):
\[\frac{\theta\sigma^2+ \bar{y}n\tau^2}{n\tau^2+\sigma^2} = \theta\frac{\sigma^2}{n\tau^2+\sigma^2} + \bar{y}\frac{n\tau^2}{n\tau^2+\sigma^2} .\]
5.4 Why no simulation in this chapter?
As you may have gathered, we love some simulations. There is something reassuring about the reality check that a simulation can provide. Yet we are at a crossroads. The Gamma-Poisson and Normal-Normal models we’ve studied here are tough to simulate using the techniques we’ve learned thus far. Letting \(\theta\) represent some parameter of interest, recall the steps we’ve used for past simulations:
- Simulate, say, 10000 values of \(\theta\) from the prior model.
- Simulate a set of sample data \(Y\) from each simulated \(\theta\) value.
- Filter out only those of the 10000 simulated sets of \((\theta,Y)\) for which the simulated \(Y\) data matches the data we actually observed.
- Use the remaining \(\theta\) values to approximate the posterior of \(\theta\).
The issue with extending this simulation technique to the Gamma-Poisson and Normal-Normal examples in this chapter comes with step 3. In both of our examples, we had a sample size greater than one, \((Y_1,Y_2,\ldots, Y_n)\). Further, in the Normal-Normal example, our data values \(Y_i\) are continuous. In both of these scenarios, it’s very likely that no simulated sets of \((\theta,Y)\) will perfectly match our observed sample data. This is true even if we carry out millions of simulations in step 3. Spoiler alert! There are other ways to approximate the posterior model which we will learn in Unit 2.
5.5 Critiques of conjugate family models
Before we end the chapter, we want to acknowledge that conjugate family models also have drawbacks. In particular:
- A conjugate prior model isn’t always flexible enough to fit your prior understanding. For example, a Normal model is always unimodal and symmetric around the mean \(\mu\). So if your prior understanding is not symmetric or is not unimodal, then the Normal prior might not be the best tool for the job.
- Conjugate family models do not always allow you to have an entirely flat prior. While we can tune a flat Beta prior by setting \(\alpha=\beta=1\), neither the Normal nor Gamma priors (or any proper models with infinite support) can be tuned to be totally flat. The best we can do is tune the priors to have very high variance, so that they’re almost flat.
5.6 Chapter summary
In Chapter 5, you learned about conjugacy and applied it to a few different situations. Our main takeaways for this chapter are:
- Using conjugate priors allows us to have easy-to-derive and readily interpretable posterior models.
- The Beta-Binomial, Gamma-Poisson, and Normal-Normal conjugate families allow us to analyze data \(Y\) in different scenarios. The Beta-Binomial is convenient when our data \(Y\) is the number of successes in a set of \(n\) trials, the Gamma-Poisson when \(Y\) is a count with no upper limit, and the Normal-Normal when \(Y\) is continuous.
- We can use several functions from the bayesrules package to explore these conjugate families:
plot_poisson_likelihood(),plot_gamma(),plot_gamma_poisson(),summarize_gamma_poisson(),plot_normal(),plot_normal_normal(), andsummarize_normal_normal().
We hope that you now appreciate the utility of conjugate priors!
5.7 Exercises
5.7.1 Practice: Gamma-Poisson
- The most common value of \(\lambda\) is 4, and the mean is 7.
- The most common value of \(\lambda\) is 10 and the mean is 12.
- The most common value of \(\lambda\) is 5, and the variance is 3.
- The most common value of \(\lambda\) is 14, and the variance is 6.
- The mean of \(\lambda\) is 4 and the variance is 12.
- The mean of \(\lambda\) is 22 and the variance is 3.
- \((y_1,y_2,y_3) = (3,7,19)\)
- \((y_1,y_2,y_3,y_4) = (12,12,12,0)\)
- \(y_1 = 12\)
- \((y_1,y_2,y_3,y_4,y_5) = (16,10,17,11,11)\)
- Tune and plot an appropriate Gamma(\(s,r\)) prior model for \(\lambda\).
- What is the prior probability that the rate of text messages per hour is larger than 10? Hint: learn about
pgamma().
- Plot the resulting likelihood function of \(\lambda\).
- Plot the prior pdf, likelihood function, and the posterior pdf of \(\lambda\).
- Use
summarize_gamma_poisson()to calculate descriptive statistics for the prior and the posterior models of \(\lambda\). - Comment on how your understanding about \(\lambda\) changed from the prior (in the previous exercise) to the posterior based on the data you collected from your friends.
\[\begin{split} Y_i | \lambda & \stackrel{ind}{\sim} \text{Pois}(\lambda) \\ \lambda & \sim \text{Gamma}(1, 0.25) \\ \end{split}\]
Plot and summarize our prior understanding of \(\lambda\).
Why is the Poisson model a reasonable choice for our data \(Y_i\)?
The
wwc_2019_matchesdata in the fivethirtyeight package includes the number of goals scored by the two teams in each 2019 Women’s World Cup match. Define, plot, and discuss the total number of goals scored per game:library(fivethirtyeight) data("wwc_2019_matches") wwc_2019_matches <- wwc_2019_matches %>% mutate(total_goals = score1 + score2)Identify the posterior model of \(\lambda\) and verify your answer using
summarize_gamma_poisson().Plot the prior pdf, likelihood function, and posterior pdf of \(\lambda\). Describe the evolution in your understanding of \(\lambda\) from the prior to the posterior.
5.7.2 Practice: Normal-Normal
- \((y_1,y_2,y_3) = (-4.3,0.7,-19.4)\) and \(\sigma = 10\)
- \((y_1,y_2,y_3,y_4) = (-12,1.2,-4.5,0.6)\) and \(\sigma = 6\)
- \((y_1,y_2) = (12.4,6.1)\) and \(\sigma = 5\)
- \((y_1,y_2,y_3,y_4,y_5) = (1.6,0.09,1.7,1.1,1.1)\) and \(\sigma = 0.6\)
- Tune and plot an appropriate Normal prior model for \(\mu\).
- According to your plot, does it seem plausible that the FancyTech stock would increase by an average of 7.6 dollars in a day?
- Does it seem plausible that the FancyTech stock would increase by an average of 4 dollars in a day?
- What is the prior probability that, on average, the stock price goes down? Hint:
pnorm(). - What is the prior probability that, on average, your stock price goes up by more than 8 dollars per day?
- Plot the corresponding likelihood function of \(\mu\).
- Plot the prior pdf, likelihood function, and the posterior pdf for \(\mu\).
- Use
summarize_normal_normal()to calculate descriptive statistics for the prior and the posterior models. - Comment on how your understanding about \(\mu\) evolved from the prior (in the previous exercise) to the posterior based on the observed data.
- What is the posterior probability that, on average, the stock price goes down? Hint:
pnorm(). - What is the posterior probability that, on average, your stock price goes up by more than 8 dollars per day?
- Prof. Abebe conducts the final exam and observes that his 32 students scored an average of 86 points. Calculate the posterior mean and variance of \(\mu\) using the data from Prof. Abebe’s class.
- Prof. Morales conducts the final exam and observes that her 32 students scored an average of 82 points. Calculate the posterior mean and variance of \(\mu\) using the data from Prof. Morales’ class.
- Next, use Prof. Abebe and Prof. Morales’ combined exams to calculate the posterior mean and variance of \(\mu\).
- Use the
footballdata to calculate the sample mean hippocampal volume and sample size of the control subjects who have not been diagnosed with a concussion. - Identify the posterior model of \(\mu\) and verify your answer using
summarize_normal_normal(). - Plot the prior pdf, likelihood function, and posterior pdf of \(\mu\). Describe the evolution in your understanding of \(\mu\) from the prior to the posterior.
- Tune and plot a Normal prior for \(\mu\) that reflects your friend’s understanding.
- The
weather_perthdata in the bayesrules package includes 1000 daily observations of 3 p.m. temperatures in Perth (temp3pm). Plot this data and discuss whether it’s reasonable to assume a Normal model for the temperature data. - Identify the posterior model of \(\mu\) and verify your answer using
summarize_normal_normal(). - Plot the prior pdf, likelihood function, and posterior pdf of \(\mu\). Describe the evolution in your understanding of \(\mu\) from the prior to the posterior.
Your friend Alex has read Chapter 4 of this book, but not Chapter 5. Explain to Alex why it’s difficult to simulate a Normal-Normal posterior using the simulation methods we have learned thus far.
To prove your point, try (and fail) to simulate the posterior of \(\mu\) for the following model upon observing a single data point \(Y = 1.1\):
\[\begin{split} Y | \mu & \sim N(\mu, 1^2) \\ \mu & \sim N(0, 1^2) \\ \end{split}\]
5.7.3 General practice exercises
- \(f(\theta) \propto 0.3^\theta 0.7^{16-\theta}\) for \(\theta\in \{0,1,2,\ldots,16\}\)
- \(f(\theta) \propto 1 /\theta!\) for \(\theta\in \{0,1,2,\ldots,\infty\}\)
- \(f(\theta) \propto \theta^4 (1-\theta)^7\) for \(\theta \in [0, 1]\)
- \(f(\theta) \propto e^{-\theta^2}\) for \(\theta \in (-\infty, \infty)\)
- \(f(\theta) \propto e^{-2\theta}\theta^{15}\) for \(\theta > 0\)
- \(f(\theta) \propto e^{\frac{-(\theta-12)^2}{18}}\) for \(\theta \in (-\infty, \infty)\)
- \(f(\theta) \propto 0.3^\theta /\theta!\) for \(\theta \in \{0,1,2,\ldots,\infty\}\)
- What model, Normal or Poisson, should you use to model the dependence of your insect count data on the underlying insect density \(\theta\)? Explain why.
- Plot the prior pdf, likelihood function, and posterior pdf of insect density \(\theta\). Comment on whether the posterior model is more in sync with the data or prior. Explain why this makes sense.
- What is the posterior mean and standard deviation of the insect density?
- Describe your posterior conclusions in context, in a way that a biologist would find helpful.
Exercise 5.19 (The Beta-Geometric model) Consider the following new Bayesian model:
\[\begin{split} Y|\theta & \sim \text{Geometric}(\theta) \\ \theta & \sim \text{Beta}(\alpha, \beta) \\ \end{split}\]
where the Geometric model has pmf \(f(y|\theta) = \theta (1 - \theta)^{y - 1}\) for \(y \in \{1,2,\ldots\}\).- Derive the posterior model for \(\theta\) given observed data \(Y = y\). If possible, identify the name of the posterior model and its parameters.
- Is the Beta model a conjugate prior for the Geometric data model?